隨著人工智能(AI)技術的飛速發展,越來越多的人希望進入這一領域,卻因技術門檻而感到迷茫。本文為零基礎的初學者提供一條清晰的學習路徑,涵蓋人工智能的全流程技術體系,并重點解釋關鍵概念如自然語言處理(NLP)、GPT、預訓練和數據標注,同時介紹基礎軟件開發的重要性。
一、人工智能全流程技術體系概覽
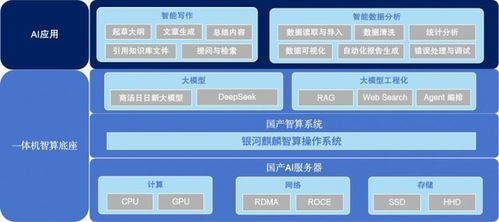
人工智能是一個多學科交叉的領域,涉及機器學習、深度學習、數據科學等多個分支。全流程技術體系通常包括以下幾個關鍵環節:
- 數據收集與處理:數據是AI模型的基石,包括獲取、清洗和標注數據。
- 模型開發與訓練:使用算法(如神經網絡)構建模型,并通過預訓練或微調優化性能。
- 部署與維護:將模型應用到實際場景中,并進行持續監控和更新。
對于初學者,建議從基礎數學(如線性代數、概率論)和編程(如Python)入手,逐步深入到機器學習框架(如TensorFlow或PyTorch)。
二、關鍵概念解析:NLP、GPT、預訓練與數據標注
在人工智能領域,特別是自然語言處理(NLP)方向,這些術語經常出現。讓我們逐一解釋:
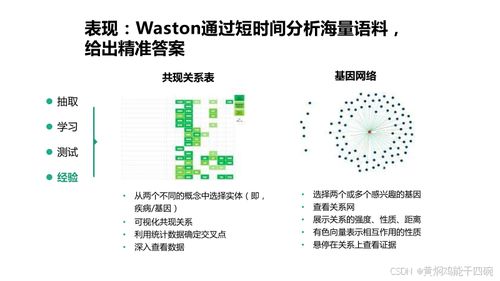
- NLP(自然語言處理):這是AI的一個子領域,專注于讓計算機理解、解釋和生成人類語言。應用包括聊天機器人、翻譯系統和情感分析。NLP依賴于機器學習模型,如循環神經網絡(RNN)和Transformer。
- GPT(生成式預訓練Transformer):由OpenAI開發的基于Transformer的模型,能夠生成連貫的文本。GPT通過大規模預訓練學習語言模式,然后通過微調適應特定任務。例如,GPT-3可以用于寫作、問答和代碼生成。
- 預訓練:指在大量通用數據上訓練模型,使其學習基礎特征(如語言結構)。預訓練模型(如BERT或GPT)可以節省時間和資源,因為開發者只需在特定數據集上微調,而不是從頭訓練。這類似讓人先學習通用知識,再專攻某個領域。
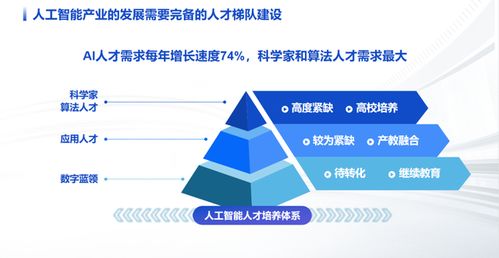
- 數據標注:這是為原始數據添加標簽的過程,例如在圖像中標記物體或在文本中標注情感。數據標注是監督學習的關鍵步驟,因為模型需要“學習”這些標簽來做出預測。常見方法包括人工標注和自動化工具,確保數據質量對模型性能至關重要。
三、人工智能基礎軟件開發
基礎軟件開發是AI實現的核心,涉及構建和優化算法、工具和系統。初學者應從以下方面入手:
- 編程語言:Python是首選,因為它有豐富的庫(如NumPy、Pandas和Scikit-learn)和框架(如TensorFlow和PyTorch)。
- 開發環境:使用Jupyter Notebook或IDE(如PyCharm)進行實驗和調試。
- 實戰項目:通過構建簡單項目(如圖像分類器或聊天機器人)鞏固知識,并學習版本控制(如Git)和部署工具(如Docker)。
四、實戰指南:從零到精通的步驟
- 入門階段:學習Python編程和基礎數學;完成在線課程(如Coursera的機器學習課程)。
- 進階階段:深入機器學習算法,實踐NLP項目;使用預訓練模型(如GPT)進行微調。
- 精通階段:參與開源項目或競賽(如Kaggle),掌握大規模數據標注和模型優化技巧。
進軍人工智能領域需要系統性學習和實踐。從理解NLP、GPT等基礎概念到掌握軟件開發技能,這條路徑能幫助零基礎者逐步成長為AI專家。記住,持續學習和動手實踐是關鍵——現在就開始你的AI之旅吧!